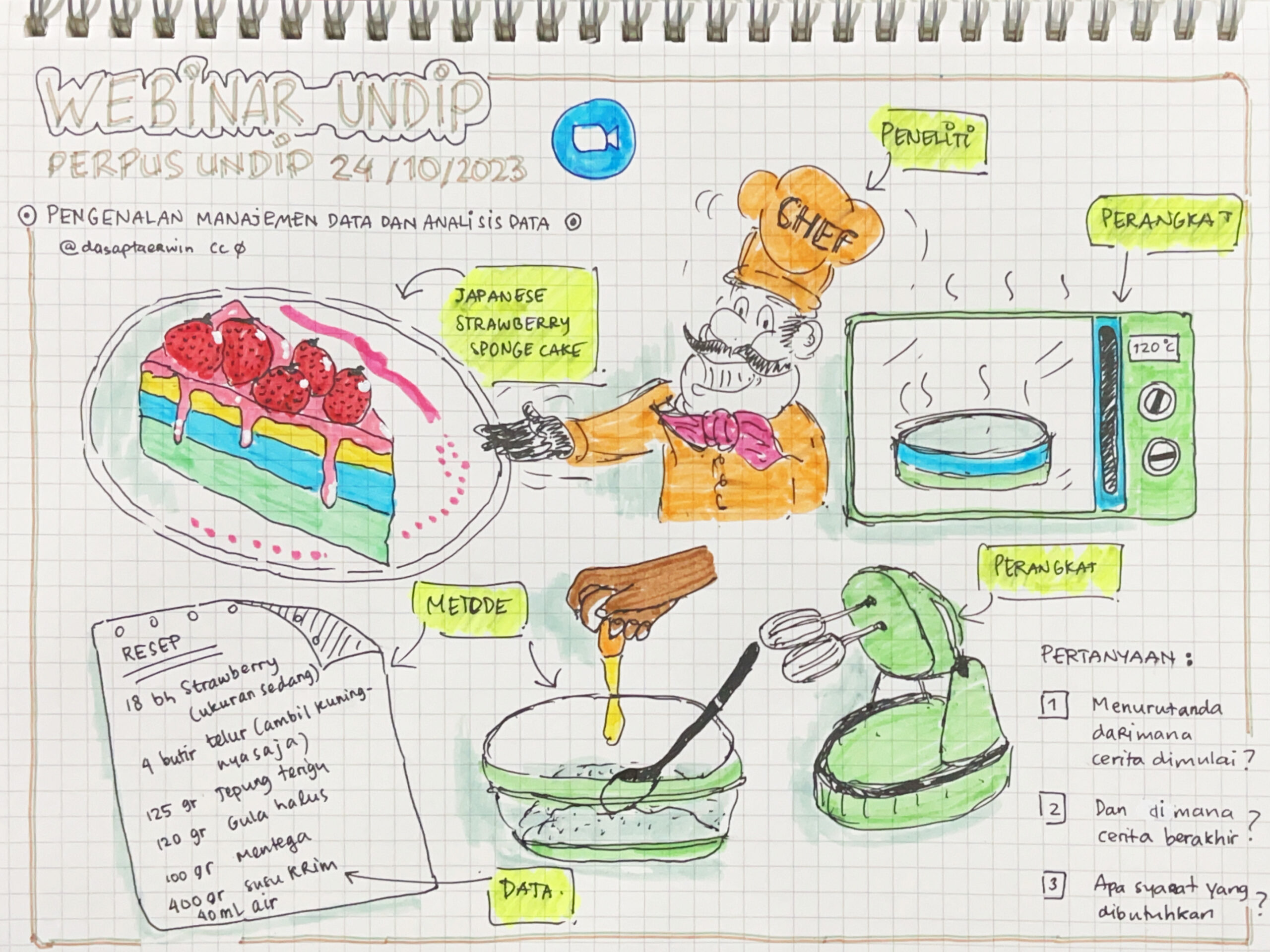
Webinar Pengenalan Pengelolaan dan Analisis Data Perpustakaan Universitas Diponegoro 24 Oktober 2023 -> Tautan Google Slides -> Tautan panduan naratif (sedang disusun)
Tag: data analysis
Ch 7: Analisis (Menulis–ilmiah–itu menyenangkan)
Blogpost ini akan sedikit lompat dari yang kemarin. Sekarang kita coba langsung ke Bab Analisis dalam proyek buku selanjutnya (WTF: (scientific) Writing is Totally Fun)….
1st Circular: Indonesia R Meet Up
Karena ternyata sudah banyak yang “terungkap” sebagai Pengguna R (pada tahap beginners hingga advanced), sudah saatnya merancang acara R meet up. Contohnya seperti ini:…
Data is the new soil
Data is not the new oil, but it’s the new soil (David McCandless, TedTalks) Anda sudah pernah lihat video Mas David McCandless di Youtube? Kalau…
Links to learn data analysis in Excel for (geology) students
(image from: homepages.spa.umn.edu) Dear friends, The following post was originated from my email to two students under my supervision. They’re both working on data analysis. Instead…
Several more things about data analysis
Outline Part 1: Data in business 1.1 Introduction 1.2 Data in business: why is it so important 1.2.1 Forecasting: we need to know the future…
Blogpost arrangement
[image from: personal collection, a path way in UWS MacArthur Campus] Dear friends, It’s another 10 degrees…