ONEsearch mungkin kalah populer dibanding kawan karib kita bersama, Scopus dan Web of Science (google sendiri tautannya ya). Bukan hanya kalah populer, sering dilupakan malah.

Saya tambahi soundtrack ya. Supaya anda sadar, di abad ke-21, membaca artikel dalam format PDF, sudah sangat membosankan, walaupun diterbitkan oleh jurnal dengan IF menembus langit ke-7.
Ini musik bebas royalti yang bisa didengarkan dan digunakan secara bebas.
Sekilas ONEsearch
Mohon maaf kalau riwayat yang sampaikan banyak kurangnya, karena memang perhatian kita sangat kurang kepada hasil kerja pakar dari Indonesia sendiri. Padahal ONEsearch ini sudah hidup sejak 2015 (cek presentasi Ismail Fahmi pendirinya) di bawah kendali Perpusnas. Ismail Fahmi sendiri sebagai inisiator telah berpengalaman dalam bidang IT, salah satunya adalah membangun sistem perpustakaan Ganesha Digital Library ITB dan kemudian baru-baru ini dengan mengembangkan Drone Emprit, yang kemudian ia kembangkan menjadi sebuah sumberdaya (resource) akses terbuka dan data terbuka. Luar biasa bukan.
Berikut roadmap awalnya yang ingin memposisikan ONEsearch seabgai portal satu pintu pencarian informasi saintifik di Indonesia.
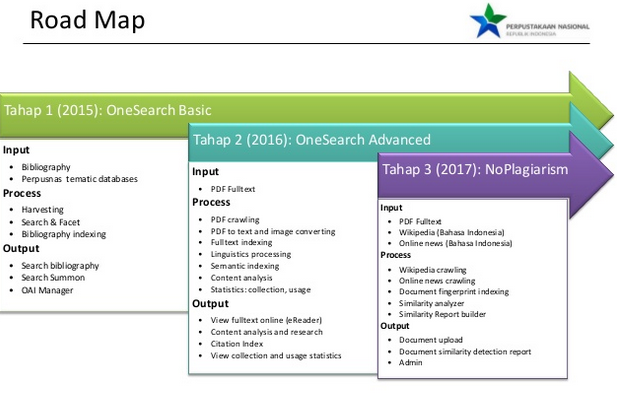 Kalau anda lihat skema di atas, bagian paling kanan, ONEsearch sudah dipikirkan agar menjadi salah satu instrumen untuk menanggulangi plagiarisme, sementara kita makin ke sini makin bersandar pada teknologi asing, misal: Turnitin dan i-Thenticate (untuk yang ini juga google sendiri ya).
Kalau anda lihat skema di atas, bagian paling kanan, ONEsearch sudah dipikirkan agar menjadi salah satu instrumen untuk menanggulangi plagiarisme, sementara kita makin ke sini makin bersandar pada teknologi asing, misal: Turnitin dan i-Thenticate (untuk yang ini juga google sendiri ya).
Apa itu ONEsearch?
ONEsearch adalah pengindeks. Pengindeks kerjanya mendata dan menampilkan dokumen sesuai dengan kata kunci yang dimasukkan pengguna.
Data dokumennya, dari mana asalnya? Dari pendaftaran para pengelola repositori daring dan perpustakaan fisik. Pendaftaran di sini tidak seperti yang anda lakukan agar diindeks kawan karib kita itu ya (S dan W). Yang dipentingkan di sini adalah infrastruktur servernya, yakni apakah menyediakan API berbasis OAI-PMH atau tidak.
Maaf saya orang geologi jadi awam sekali. Pendek kata fitur itu mengakibatkan data dokumen yang dalam suatu repositori atau jurnal dapat dibaca oleh orang lain, yakni pengindeks dan kemudian ditampilkan ke dalam hasil pencariannya.
Mengapa perlu ONEsearch sebagai pengindeks?
Satu-satunya alasannya adalah bahwa kala itu, data dokumen di berbagai repositori daring dan perpustakaan fisik, baik yang ada di lembaga penelitian, pusat-pusat penelitian dan pengembangan (puslitbang kementerian), maupun yang ada di universitas belum terhubung. Lihat slide di bawah ini.
 Kala itu kondisinya seperti pada slide di bawah ini.
Kala itu kondisinya seperti pada slide di bawah ini.
 Kalau kita periksa saat ini, maka Portal Garuda, ISJD, dan Garuda.dikti.go.id, telah menyatu menjadi Garuda Ristekdikti yang berfungsi mengindeks jurnal ilmiah. Per hari ini 31 Mei 2019 pkl 15.00, Garuda mengindeks 810 ribu lebih artikel, dari 7200 lebih jurnal, 130 lebih konferensi, yang diterbikan oleh 1100 lebih penerbit, yang dapat dikategorikan ke dalam 40 bidang ilmu.
Kalau kita periksa saat ini, maka Portal Garuda, ISJD, dan Garuda.dikti.go.id, telah menyatu menjadi Garuda Ristekdikti yang berfungsi mengindeks jurnal ilmiah. Per hari ini 31 Mei 2019 pkl 15.00, Garuda mengindeks 810 ribu lebih artikel, dari 7200 lebih jurnal, 130 lebih konferensi, yang diterbikan oleh 1100 lebih penerbit, yang dapat dikategorikan ke dalam 40 bidang ilmu.

Masif bukan. Masih kurang bangga bagaimana? Hidup Indonesia.
Sebagai bandingan Scielo, pengindeks dari Amerika Latin, sejak tahun 2002 hingga saat ini baru mengindeks 1100 an jurnal dari 16 negara. Jumlah ini sudah sangat tinggi dibandingkan dengan kondisi di Eropa. Simak presentasi Jon Tennant, pendiri Preprint Server Paleorxiv dan OpenScienceMOOC ini.
Bandingkan juga dengan JStage, pengindeks regional Jepang. Sampai dengan tahun 2012, ia baru mengindeks 1300 an jurnal.

Siapa saja mitra ONEsearch?
Banyak sekali, kalau dihitung menurut jenisnya ada hampir 2000 institusi, hampir 1500 perpustakaan, dan hampir 6000 repositori.

Apa saja fitur ONEsearch?
Awalnya memang baru pengindeks. Tapi kemudian berkembang pesat. Saya sendiri baru menyadarinya dua hari lalu, sebelum akhirnya saya mulai menulis artikel ini. Dua hari lalu saat saya google, belum ada yang mengulas perkembangannya.
Kembali ke fitur. Ada fitur IOS Links, yang terdiri dari IOS Explorer, IOS CiteMiner, dan IOS Reporting.
Apa saja manfaat ONEsearch?
Para pembuatnya mengklaim ini. Saya setuju. Bagaimana dengan anda?

IOS Explorer
IOS Explorer ini fitur canggih yang menganalisis hubungan antara kata (mohon masukan kalau saya salah). Kita coba langsung saja ya. Andai kita masukkan kata-kata “geologi”, maka akan muncul berbagai kata yang terkait dengan itu secara hirarkis. Seperti ini.
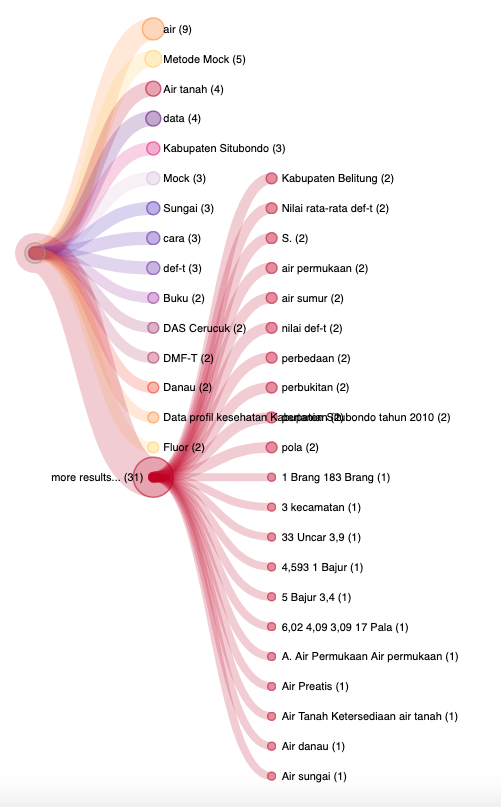 Lebih hebatnya lagi, kita bisa tahu sampai ke lokasi dokumen ada di mana. Sayangnya ITB tidak masuk di dalamnya. Saya belum tahu sebabnya, karena ITB sudah masuk dalam daftar mitra. Apakah karena data tesis/disertasinya masih dikunci, tidak dapat dibaca mesin. Mungkin itu.
Lebih hebatnya lagi, kita bisa tahu sampai ke lokasi dokumen ada di mana. Sayangnya ITB tidak masuk di dalamnya. Saya belum tahu sebabnya, karena ITB sudah masuk dalam daftar mitra. Apakah karena data tesis/disertasinya masih dikunci, tidak dapat dibaca mesin. Mungkin itu.
Saya tambahkan contoh lagi ya, mumpung libur. Menggunakan fitur “IOS explorer”, saya mendapati spektrum ilmu geologi (kata kunci: “geologi”) selain terkait dengan kata kunci-kata kunci lain di bidang geologi lainnya, ternyata berkaitan hingga ke PAD (pendapatan asli daerah) dan tanaman tembakau. Apakah Scopus dan Web of Science bisa melakukan ini? Saya jawab cepat dan pasti, tidak bisa. 🙂

Silahkan anda eksplorasi lagi ya. Dan ceritakan hasilnya ke saya.
IOS Citeminer
FItur ini menambang (mining) data rekaman dokumen, ada di mana posisinya plus bagaimana hubungan antara dokumen. Hubungan yang saya maksud antara lain adalah:
- hubungan sitasi: satu dokumen disitir oleh berada dokumen, dokumen apa.
- hubungan antar penulis: ada berapa dokumen yang ditulis oleh tim penulis yang sama, bagaimana jejaring penulis A dengan penulis lain, dst.
- hubungan instansi antar penulis
- dan beberapa visualisasi lainnya.
Untuk kata kunci “geologi” berikut hasilnya.
Untuk grafik jejaring institusi penulis:
 Gambar di atas dibangun dari beberapa sumber data sbb. Ini dapat dilihat di panel sebelah kiri.
Gambar di atas dibangun dari beberapa sumber data sbb. Ini dapat dilihat di panel sebelah kiri.
 .
.
 .
.
 .
.
 .
.
Saking banyaknya fitur, belum selesai saya eksplorasi. Silahkan anda coba sendiri. Jangan lupa sampaikan ke saya hasilnya ;).
IOS Reporting
Kalau ini adalah fitur yang melaporkan kinerja IOS, hingga berbagai dampak penggunaan IOS. Berikut ini hanya beberapa contohnya.
Ringkasan statistik
 .
.
Statistik pengunjung. Banyak sekali yang berkunjung ke ONEsearch setiap harinya, tapi saya heran belum ada yang mengulasnya. Padahal ini hal yang layak sekali diulan dan disebarkan. Kontradiksi dengan kebiasaan kita yang menyebarkan berita bohong (hoax) dengan cepat tanpa berpikir dua kali. Sementara untuk menyebarkan hal yang baik berpikir beribu kali.
 .
.
Perangkat lunak yang paling banyak dipakai
 .
.
Pertumbuhan jumlah dokumen yang diindeks
Yang saya tampilkan ini adalah untuk kategori repositori.
 Sangat banyak bukan.
Sangat banyak bukan.
Bagaimana ini semua bisa dilakukan?
Tentunya ONEsearch tidak bekerja sendiri. Mereka bisa hidup, karena ada banyak institusi yang membuka diri dengan cara membuka koleksinya.
Masalah membuka diri (baca membuka data) ini juga beragam kondisinya. ONEsearch bisa sampai memetakan keterkaitan kata, karena dokumen yang disampaikan lengkap dan dapat dibaca mesin. Jadi kalau perpustakaan atau instansi ada yang hanya membuk abstrak dokumen saja atau bahkan hanya menyediakan berkas dalam format PDF yang tidak dapat dibaca mesin.
Penutup
Jadi perlu kesadaran juga dari institusi untuk membuka data. Kalau ini dilakukan, maka tidak hanya pengguna atau pembaca yang senang, tapi institusi juga senang. Akan ada banyak yang mengakses situsnya.
Sekarang ini sudah abad ke-21, tapi anda masih bersikap seolah ini masih abad ke-17 atau bahkan seperti zaman manusia pra-sejarah. Semua masih rahasia dan dirahasiakan.
Terima kasih Pak Ismail Fahmi dan Tim ONEsearch.
Gambar ini sangat relevan.
